
The Best Stable Diffusion Models

Introduction
Stable Diffusion AI empowers users to generate images based on straightforward text prompts. Its name, "stable," originates from its proficiency in generating clear, non-blurry images. Like other AI tools, however, achieving optimal results with Stable Diffusion AI necessitates training models.
This is where Stable Diffusion models play a crucial role. These models serve as the foundation for AI training, with stable diffusion models providing the necessary stability and consistency for effective learning. Given the extensive array of available art styles, having models that ensure consistency for the AI to follow is essential. This article will explore different Stable Diffusion models available for use and delve into the realm of Stable Diffusion AI, highlighting the significance of stable diffusion models in facilitating AI training and artistic creation.
Part 1. Exploring Stable Diffusion AI
As previously noted, Stable Diffusion represents an artificial intelligence that comprehends text prompts, skillfully translating them into intricate and detailed images. Functioning as a diffusion model, stable diffusion models like Stable Diffusion XL commence with a random and initially blurry image, progressively enhancing its detail according to the provided text and its underlying model until it aligns with the prompt. Through the utilisation of stable diffusion models, such as Stable Diffusion XL, users can witness the gradual refinement of images as the AI dynamically adjusts based on the input text, resulting in visually striking outcomes.
Stable Diffusion is renowned for its exceptional capacity to produce lifelike images, showcasing its proficiency in replicating various art styles with precision.
Real-Life Applications of Stable Diffusion
All of these advancements require extensive training for the AI. By leveraging deep learning algorithms, such AIs can craft unique and accurately prompt-based images. This proficiency has made Stable Diffusion AI invaluable in various fields:
- Advertising: Stable Diffusion has revolutionised advertising by enabling the creation of professional-grade images suitable for diverse campaigns. This capability empowers companies to introduce products without the need for elaborate professional photoshoots.
- Entertainment: With the ability to generate images based on specific art styles, Stable Diffusion proves invaluable to entertainment studios. This reduces the workload significantly, allowing for the swift development of stunning background images essential for movies, comics, digital art, and similar mediums.
- Education: Stable Diffusion serves as a visual aid in education, providing depictions of historically significant events or other complex subjects that may be challenging to access otherwise. While these depictions may not always be entirely accurate, they serve as effective tools to ignite children's interest. Additionally, fields such as medicine and science can benefit greatly from this visualisation capability.
Stable Diffusion Models
Initially, distinguishing between the terms "stable diffusion" and "stable diffusion models" might pose a challenge. However, the primary distinction lies in the fact that "stable diffusion" denotes the technology itself—it represents the process. Conversely, "stable diffusion models" pertain to the training or reference data that the AI employs within this process. For instance, these models could be categorised as realistic, stylized, and so forth.
Regardless of the type, these stable diffusion models grant users control over the image generation process of Stable Diffusion AI. Without such guidance, the AI might interpret text differently from the intended meaning. Hence, furnishing a suitable model for the AI proves crucial, significantly streamlining the process and ensuring that the generated images align with the user's intentions. With the utilization of stable diffusion models, users can effectively guide the AI in interpreting text prompts accurately, resulting in images that closely match their desired outcomes.
Part 2. 9 Best Stable Diffusion Models
In this section, we will delve into various stable diffusion models curated to facilitate your quest for the ideal option. Each of these models has been carefully selected to guarantee superior quality in image generation. Furthermore, they can be accessed conveniently on reputable platforms such as Dashtoon Studio, CivitAI.com and HuggingFace.co, both renowned websites for stable diffusion models.
Dashtoon Studio
Dashtoon Studio, an AI-driven comic creation platform, streamlines the comic-making journey by offering an array of user-friendly features, including stable diffusion models. It provides access to a character library or the option to craft your characters, diverse art styles, and AI-powered tools for various tasks including storyboard conversion, background removal, facial adjustments, and image upscaling. This platform empowers comic creators to effortlessly bring their visions to life, ensuring a swift and hassle-free start with the aid of stable diffusion models. Additionally, users can engage with fellow creators through the Dashtoon Studio Discord Community. It's the long-awaited AI comic creator that revolutionises comic creation, making it a seamless endeavour with stable diffusion models.

MeinaMix
MeinaMix is a complimentary anime diffusion model designed to produce top-tier images with minimal input. Its primary aim is to deliver high-quality results while maintaining a realistic approach to the anime art style. Give it a try to effortlessly craft images featuring your beloved anime characters or scenic locations.
DreamShaper
DreamShaper is crafted to produce images reminiscent of paintings, infused with elements inspired by anime. It excels at crafting characters against captivating backdrops, creating visually stunning scenes. True to its name, DreamShaper aims to generate ethereal textures imbued with a fantastical aura. Give it a try if you're seeking to bring your fantasy characters to life with a touch of dreaminess.
AnythingXL
AnythingXL presents a lively and enjoyable approach to anime image generation. Offering a diverse array of anime art styles, it has the ability to craft captivating anime characters and backgrounds with either a realistic touch or vibrant, colorful aesthetics. This versatile model is capable of virtually generating any visual concept you desire, making it a valuable tool for creative endeavours.
Realistic Vision V6.0
Realistic Vision stands out as the most popular photorealistic stable diffusion model accessible on civitai, boasting the highest number of downloads. Its exceptional capacity to capture intricate details in generated images renders it a premier selection for photorealistic diffusion. What distinguishes this model from others is its unparalleled capability to produce images with remarkable precision and detail.
CyberRealistic
CyberRealistic Negative represents an AI model adept at generating detailed and lifelike images based on text inputs. It's a refined iteration of Stable Diffusion, leveraging a diffusion process to enhance images from noise gradually. Trained on a vast dataset, the model can generate both safe-for-work and not-safe-for-work images of satisfactory quality. However, being in the training phase, occasional artefacts or errors may occur. Accessible on platforms like Hugging Face and Civitai, users can experiment with various parameters and prompts. An innovative feature, CyberRealistic Negative, enhances image realism by allowing users to input negative prompts. These prompts instruct the model to avoid generating undesirable features or artefacts in the images.
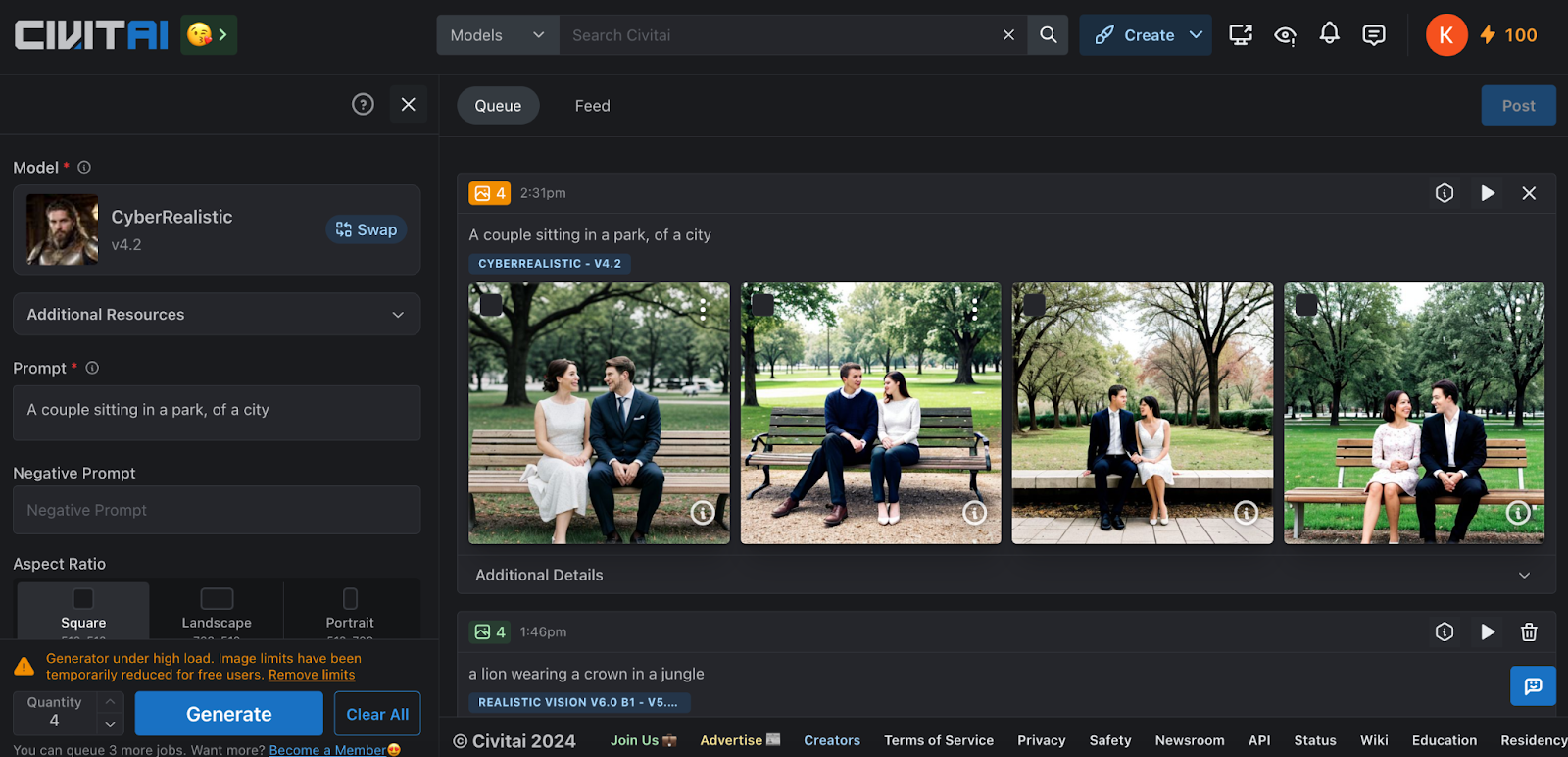
[Lah] Mysterious | SDXL
The model conjures a fantasy ambiance with a predominant influence from Asian culture, yet it maintains notable traces of Western civilization. Emphasising fantasy aesthetics, it enriches images with historical and cyberpunk elements while integrating information about mythical creatures. Anticipated to evoke imaginative realms, it offers depictions ranging from ancient epochs to futuristic urban landscapes.
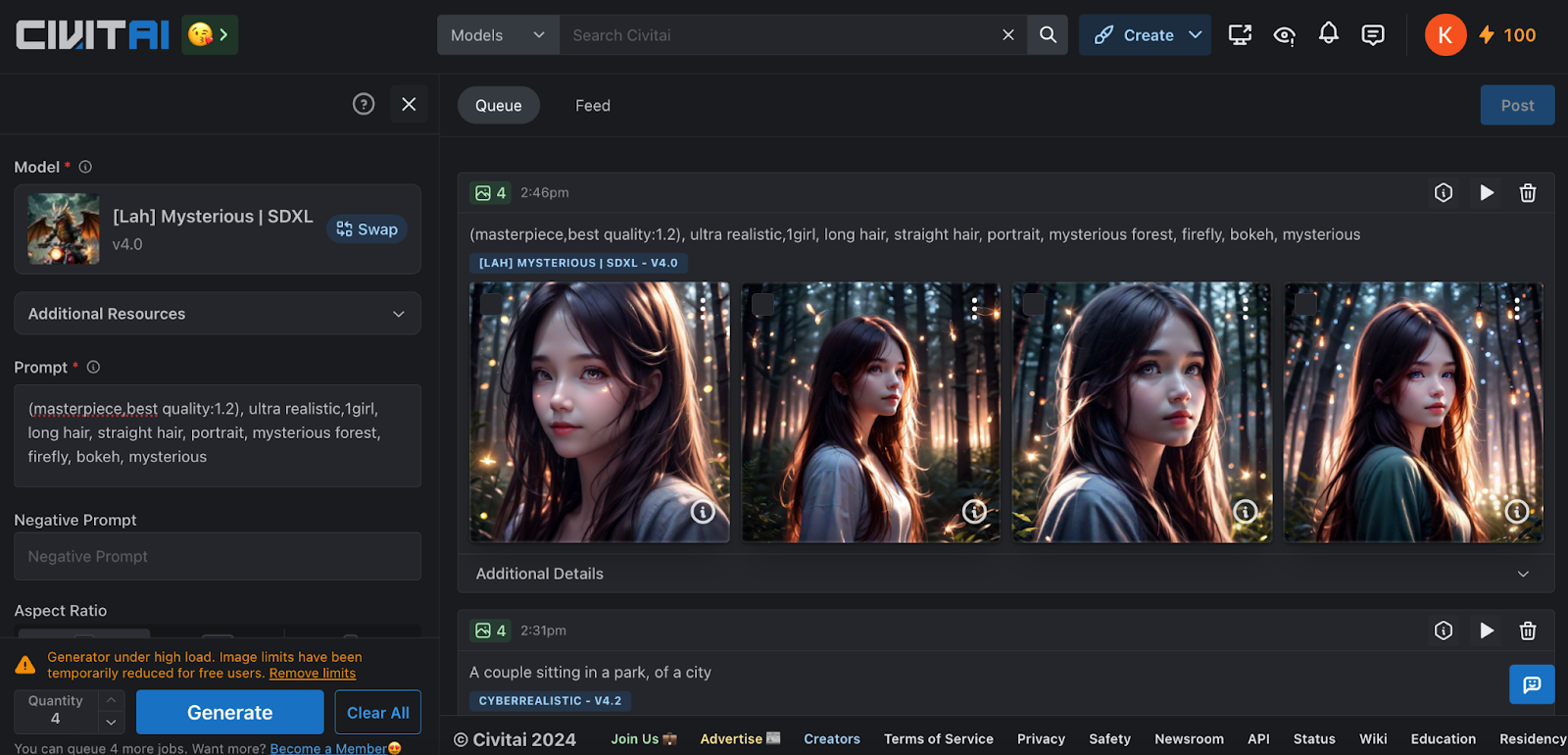
Flat-2D Animerge
This amalgamation combines various anime and cartoon-based models to create a semi-cartoony anime style, closely resembling what is typically seen in anime rather than the commonly found hyper-detailed anime models. Prompting this model is straightforward and doesn't necessitate extensive prompt engineering to yield satisfactory outcomes.
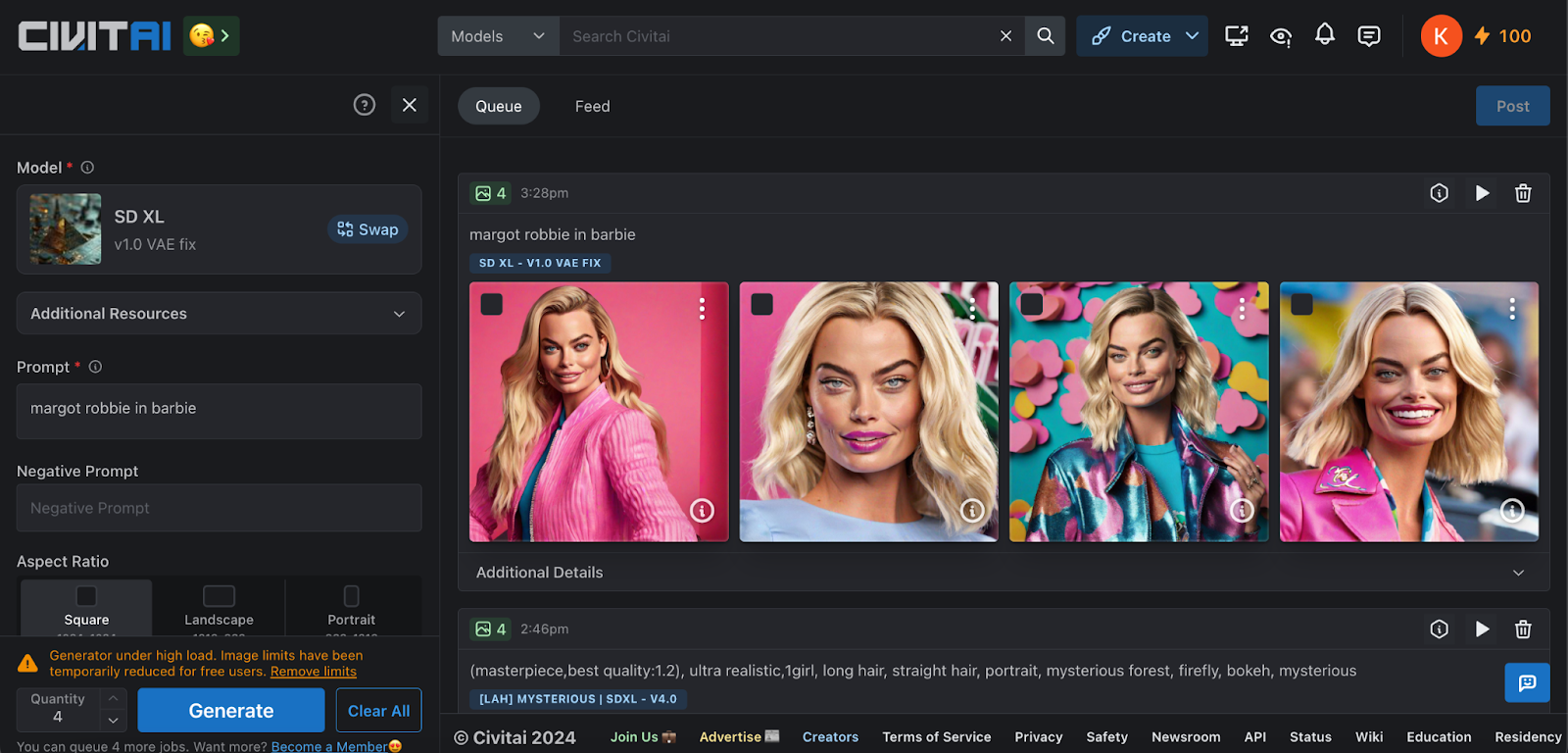
SD XL
The model exhibits strong realism capabilities while also offering a diverse array of styles. In fact, I've shared all the available styles that can be generated using this Stable Diffusion model. The SDXL model comprises two components: the base model and the refiner model. To utilise both, you may need to load them separately in Automatic1111 or opt for ComfyUI. Overall, SDXL proves to be a versatile option, capable of generating a wide range of content. However, it's essential to acknowledge that the model may struggle with generating legible text and isn't adequately trained for NSFW image generation.
Dreamshaper XL
If you enjoy working with SDXL models, consider experimenting with DreamShaper XL, which is a variant of the DreamShaper model mentioned earlier. In contrast to the official SDXL model, DreamShaper XL eliminates the need for a refiner model. With this model, you can create superior depictions of humans, animals, objects, landscapes, and dragons. I've found this model to be ideal for producing intricately detailed images that can be upscaled to exceptional quality, resulting in stunning visuals. Moreover, the model seamlessly integrates with SDXL LoRA models, offering versatility in exploring various styles.
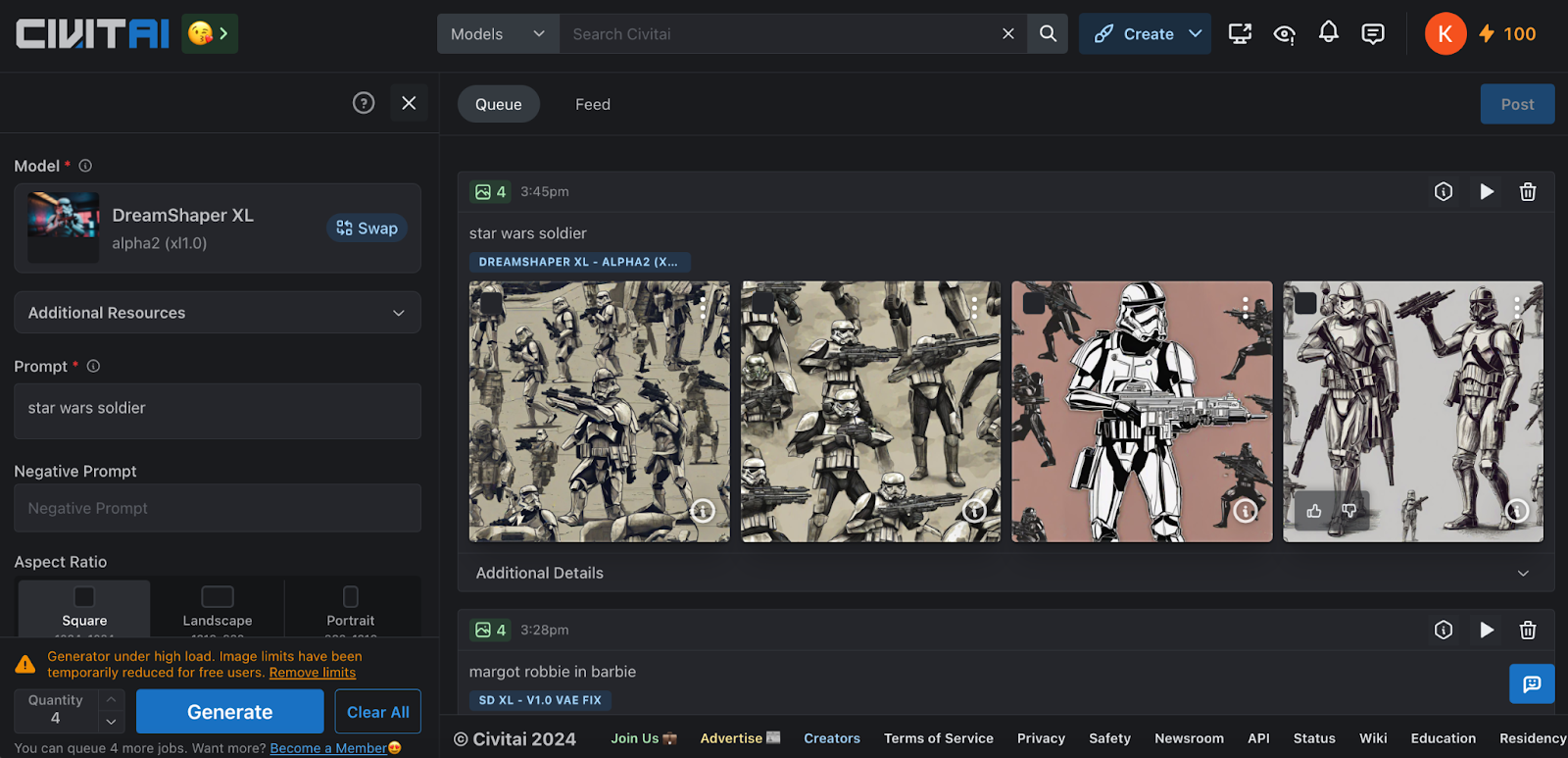
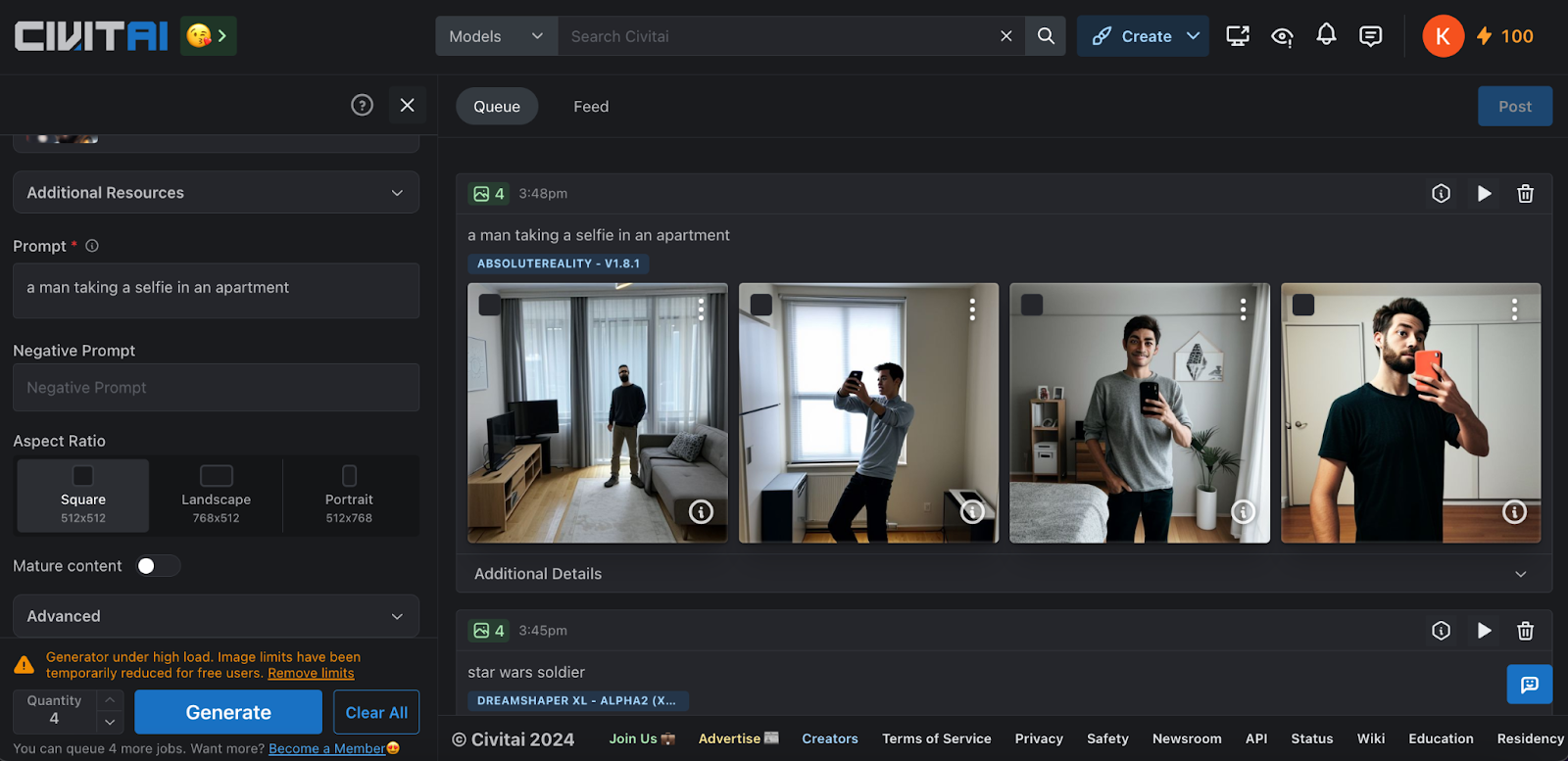
Absolute Reality
The AbsoluteReality model originates from the same developer responsible for the DreamShaper model. While both models share similarities, AbsoluteReality prioritises realism, contrasting with DreamShaper's focus on artistic expression. Additionally, AbsoluteReality is particularly effective with concise and straightforward prompts, making it well-suited for beginners who prefer simplicity in their interactions with AI models. Notably, the model excels in producing aesthetically pleasing facial renderings and integrates seamlessly with face model LoRAs, facilitating the creation of captivating portraits. Moreover, it demonstrates consistent accuracy in depicting body anatomy and produces intricately detailed eyes. Overall, I appreciate this model for its remarkable ability to generate lifelike human representations.
Conclusion
Stable diffusion AI represents a powerful asset capable of revolutionising image creation and utilisation. When selecting a stable diffusion model, it's crucial to consider your specific requirements. For instance, a model trained on facial images excels in producing lifelike portraits compared to a model trained on landscape photos.